表达式全集

正则表达式有多种不同的风格。下表是在PCR…
正则表达式有多种不同的风格。下表是在PCR…

防止GetRight和Curl来抓取网內的数据的代…

一些regular的tips: 1 非贪婪flag [code …

出处 python 中的re 模块 正则表达式 就个…

匹配所有中文字符的正则表达式是/[一-龥]/…
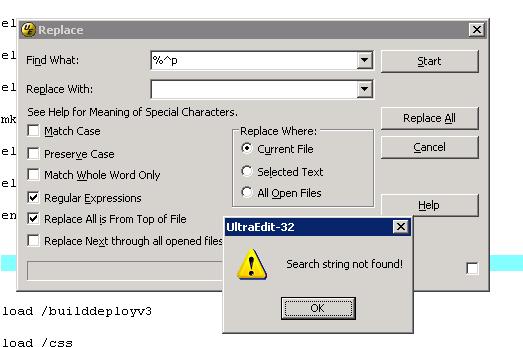
有P说ultraedit的正则不能用了,还发了图…

find path -option [ -print ] [ -exec -o…

用了这个软件很长时间了。写程序啥的都用…

ultraedit style regular expressions 查…

1. grep简介 2. grep正则表达式元字符集(…