oracle通过dblink调用远程的存储过程procedure

oracle通过dblink调用远程的存储过程proce…
oracle通过dblink调用远程的存储过程proce…

有时候用oracle的数据库,插入数据的时候…

mysql有一个replace into的dml语句,类似i…

oracle里面有一个decode的函数,顾名思义…

工作中经常遇到身份证要从15位转换到18位…

查看当前oracle时间的格式 select * from …

原来写过一个程序,需要按照数据的更新日…
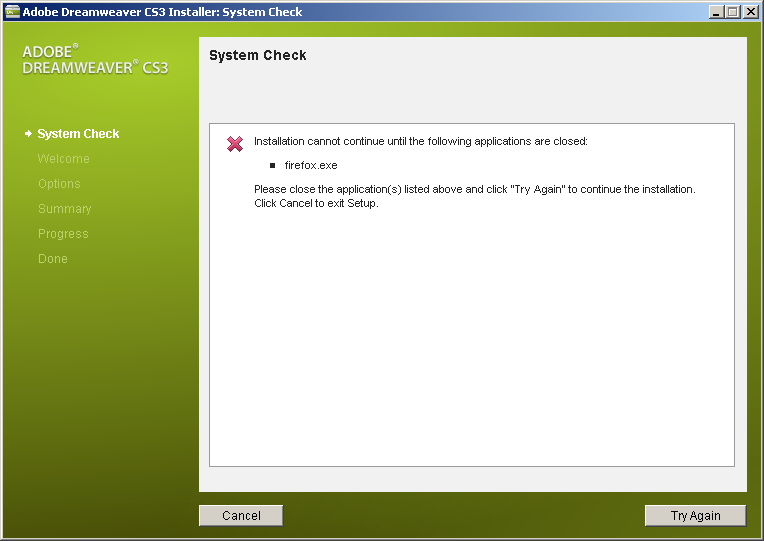
有时候操作数据库会被锁掉,表现就是对表…

一张多用户的通讯记录表,主要是手机信息…

1. /*+ALL_ROWS*/ 表明对语句块选…